

Tab_study에서 공부한 AI 결정 트리에 대해 정리해보려한다.
결정 트리(Decision tree)란?
결정 트리는 분류, 회귀 등에서 사용하는 지도학습에 대한 학습 모델이다. 기본적으로 결정 트리는 예/아니오 질문을 이어 나가면서 학습한다.
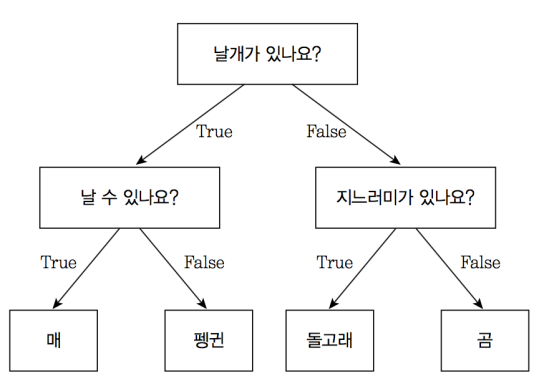
위의 사진처럼 결정 트리는 질문에 의해 학습을 이어나간다. 코드를 통해 확인해보자.
결정트리 사용해보기
데이터 준비하기
1
2
3
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data') # wine 데이터
1
2
wine.info()
wine.describe()
1
2
3
4
5
6
7
8
9
10
11
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6497 entries, 0 to 6496
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 6497 non-null float64
1 sugar 6497 non-null float64
2 pH 6497 non-null float64
3 class 6497 non-null float64
dtypes: float64(4)
memory usage: 203.2 KB
| alcohol | sugar | pH | class | |
|---|---|---|---|---|
| count | 6497.000000 | 6497.000000 | 6497.000000 | 6497.000000 |
| mean | 10.491801 | 5.443235 | 3.218501 | 0.753886 |
| std | 1.192712 | 4.757804 | 0.160787 | 0.430779 |
| min | 8.000000 | 0.600000 | 2.720000 | 0.000000 |
| 25% | 9.500000 | 1.800000 | 3.110000 | 1.000000 |
| 50% | 10.300000 | 3.000000 | 3.210000 | 1.000000 |
| 75% | 11.300000 | 8.100000 | 3.320000 | 1.000000 |
| max | 14.900000 | 65.800000 | 4.010000 | 1.000000 |
데이터를 확인해보면 결측치는 없는 것으로 확인 된다.
데이터 나누기
1
2
3
4
from sklearn.model_selection import train_test_split
data = wine.drop(columns=["class"])
target = wine["class"]
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
데이터 전처리
1
2
3
4
5
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
결정트리 모델로 학습시키기
1
2
3
4
5
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
1
2
0.996921300750433
0.8592307692307692
결정 트리의 스코어를 확인해봤을때 약간의 과대적합이 보인다.
결정트리 모델 시각화 해보기
1
2
3
4
5
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
 결정 트리의 max_depth를 조절해 결정트리를 자세히 확인해보자
결정 트리의 max_depth를 조절해 결정트리를 자세히 확인해보자
1
2
3
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol','sugar','pH'])
plt.show()
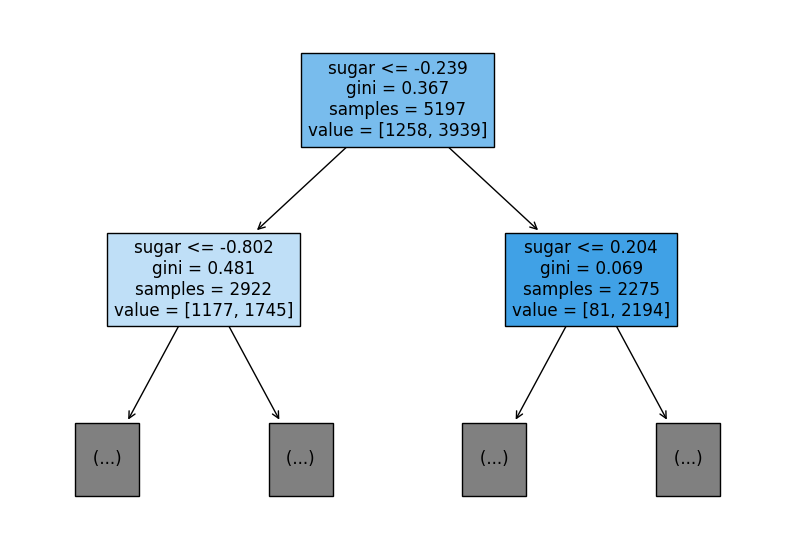 plot_tree의 매개변수를 확인해보면 max_depth는 트리의 높이를 제한할 수 있고, filled를 통해 트리 노드 색칠 여부, feature_names를 통해 트리의 각 노드에서 어떤 피처가 사용되는지 확인할 수 있다.
plot_tree의 매개변수를 확인해보면 max_depth는 트리의 높이를 제한할 수 있고, filled를 통해 트리 노드 색칠 여부, feature_names를 통해 트리의 각 노드에서 어떤 피처가 사용되는지 확인할 수 있다.
max_depth 조절하고 스코어 확인해보기
1
2
3
4
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
1
2
0.8454877814123533
0.8415384615384616
테스트 스코어의 점수는 낮아졌지만 과대적합 문제를 해결한 것을 볼 수 있다.
feature importances_(특성들의 중요도)
1
print(dt.feature_importances_)
1
[0.12345626 0.86862934 0.0079144 ]
dt.feature_importances를 통해 각 피쳐들의 중요도를 확인할 수 있는데 ‘alcohol’,’sugar’,’pH’ 중 2번째 특성이 sugar의 중요도가 가장 높은 것을 확인할 수 있다.
지니 불순도
$지니불순도=1-(음성클래스 비율^2 + 양성클래스비율^2)$
지니 불순도는 결정 트리 모델에서 데이터의 분할을 결정하고, 모델의 품질을 평가하는 데 사용되는 중요한 지표 중 하나이다. 낮은 지니 불순도를 가진 노드가 모델의 분류 작업에서 더 효과적인 분할을 나타내며, 이를 통해 모델이 더 나은 예측을 수행할 수 있다.
느낀점
결정트리에 대해 공부해보면서 각 질문들을 통해 모델이 학습을 하여 예측한다는 것에 신기함을 느꼈고 분류, 회귀를 모두 하는 모델이므로 결정트리는 중요한 모델이라는 것을 느꼈다.